2.7 Setting Up a Data Pipeline
The data pipeline allows automating data ingestion, transformation, ML prediction, and export. You can chain various components in some logical sequence to automate data processing. The data pipeline runs in two modes: On Demand and Scheduled (described below). The data pipeline also allows to attach a custom processor that is build using the Processor interface and packaged as Jar file (more on custom processor below).
A data pipeline is a sequence of execution of one or more data processing units. For example, a data pipeline may contain one or more ingesters, transformer, custom processing, ML models and emitter.
To create a data pipeline:
- Create one or more ingesters. See Instructions here.
- Create a transformer that may contain one or more SQL statements within it. Only one transformer per pipeline is allowed. Therefore, all relevant SQL statements must be included in a single transformer. See instructions on how to create a transformer containing multiple SQL statements.
- If your data processing needs any custom processor, create one to be included in the pipeline. See instructions on how to create a processor.
- Create an emitter if the processed data need to be stored outside of Momentum storage (for example, index in Impulse EDW, MongoDB, MySQL, Oracle etc). See instructions on how to create an emitter.
- Create a data pipeline and add all required components to it. See below for more details.
A few example pipelines:
- one or more ingesters –> one transformer –> one or more processors –> one emitter
- one or more ingesters –> emitter
- one transformer –> emitter
- one transformer –> one or more processors –> emitter
- a single ingester –> emitter
- one or more ingesters –> one transformer –> one or more ML models –> one emitter
If emitter is omitted, the processed data of the pipeline is stored within the distributed data lake based on HFDS, the main storage system that Momentum utilizes for storing files.
Creating A Data Pipeline
- Expand “Data Pipeline” menu (under ETL section) from the main menu options –> click “Pipeline Home”.
- Click “Create New Pipeline” from the top menu options
- Fill out the form fields:
- Name: a user defined unique name to identify the pipeline
- Core: Number of cluster cores to execute the pipeline job in distributed and parallel mode. For a big dataset and complex pipeline execution, allocate as much core as you have it available to speed up the execution.
- Memory: RAM per core. 4GB default works for most cases. Tune if required.
- Output Format: If no emitter is attached to this pipeline, the data is stored within the Momentum’s distributed file system (HDFS). Specify the output file format.
- Run Mode:
- On demand: The pipeline needs to be manually executed by clicking the “Run” button.
- Scheduled: Specify a Linux style cron expression to schedule the execution of the pipeline in an automated mode. Here is an online tool to create cron expressions.
- Storage mode: Used only if no emitter is attached to this pipeline.
- Log Input and output Count: If select yes, it will generate the count of processed data for auditing and inventory purpose. This is an expensive process and should be avoided if count is not necessary.
- Submit the form to save it.
- Once the pipeline form is submitted, you will need to add processing units to it. Here are the steps:
- Add one or more ingesters: expand ingester menu –> click on the ingester you want to add –> a rectangular widget is added on the main canvas.
- Add a transformer: expand transformer menu –> click on the transformer you want to add –> a rectangular widget is added on the main canvas.
- To add one or more ML Models, expand the ML models from the left menu panel and click on the models you want to add to the pipeline.
- To add a new processor (not already created): Click “Add Processor” button located at the top of the pipeline canvas. Fill out the form to add to the canvas.
- To add an existing processor: expand process menu –> click on the processor you want to add –> a rectangular widget is added on the main canvas.
- To add a new emitter (not already created): Click “Add Emitter” button located at the top of the pipeline canvas. Fill out the form to add to the canvas. For details on the form field, see the Emitter section of this wiki.
- To add an existing emitter: expand emitter menu –> click on the emitter you want to add to the canvas –> a rectangular widget is added on the main canvas.
- If needed, move the widgets around to organize. Widgets may overlap if the canvas size is small. Drag the overlapped widgets to separate them out.
- Once all widgets are laid out on the canvas, connect them by clicking on the output tip of one widget to the input tail of the other widget. See Figure 2.11 below for an example pipeline with connected units.
- To connect the units, click on the “out” tip and drag the arrow and click on the “in” tip.
- Save the pipeline by clicking the “Save” button. You may need to scroll down to see the “save” button.
Running Data Pipeline
To run the data pipeline:
- From the pipeline home page, click on the checkbox corresponding to the pipeline you want to run.
- Click “Run” button located at the top menu bar.
- When the pipeline starts running, it will show the status of execution of each unit that are included in the pipeline. When all the units complete execution, the pipeline status will show as “complete” and result as “success”.

Figure 2.10: Screen showing pipeline home and menu options
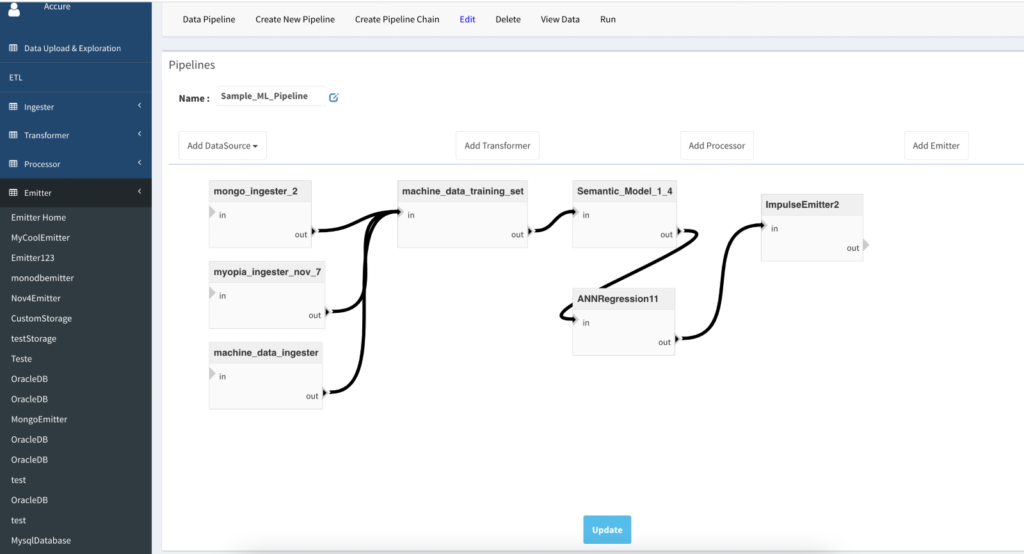
Figure 2.11: Example pipeline with the connected units (3 ingesters connected with one transformer who output feeds to semantic model that in turn feeds to ANN regression model. The final output is exported to Impulse emitter.
Important Notes:
1. A pipeline can contain only one transformer. If you need multiple transformers, write multi-step SQL statements (see Transformer section for details).
2. Only those models that are deployed to MLOps can be included in the pipeline. If multiple versions of the same model is deployed, it will use the latest version for prediction.