2.4 Transformer
Momentum provides SQL-based interface for data transformation. Data cleaning, null removal, datatype conversion, column renaming, mathematical transformation, blending, merging, joining with multiple data sources are some of the transformation tasks that can be performed over data created within Momentum. Anything that is supported by ANSI-standard SQL can be performed using Momentum’s transformation engine. A multi-level SQL based transformation is a powerful way of performing complex transformation tasks involving single or multiple data sources.
In this section we will explore how to perform a single SQL-based as well as multi-step transformations.
Single Step Transformer
In the following example, binary formatted date is transformed into human readable date using standard SQL. To do this:
- Form the left hand side navigation panel, expand Transformer” and then click “Transformer Home”.
- Click “New Transformer” located at the top menu option. The transformer window opens.
- The transformer window is divided into two sections:
- The left side section containing a form is used to write transformation SQL, and
- the right-side section shows all data created within Momentum by various components. Clicking on any of the data sources will display 100 rows of data by default. When the data is displayed, it shows a query block at the top where you can write any SQL statements on top of this datasource to test out any potential transformation query. This view is provided to look at the data while writing the transformation query on the left side section. See Figure 2.5 below for an example.

Figure 2.5: View showing 100 records of data to help in writing transformation SQL on the left section
- Notice that the DATE column in the above screenshot is in binary format. We will write SQL to transform that column to a human readable date format. Fill out the form on the left section to configure the transformer as described below (and shown in Figure 2.6 below)
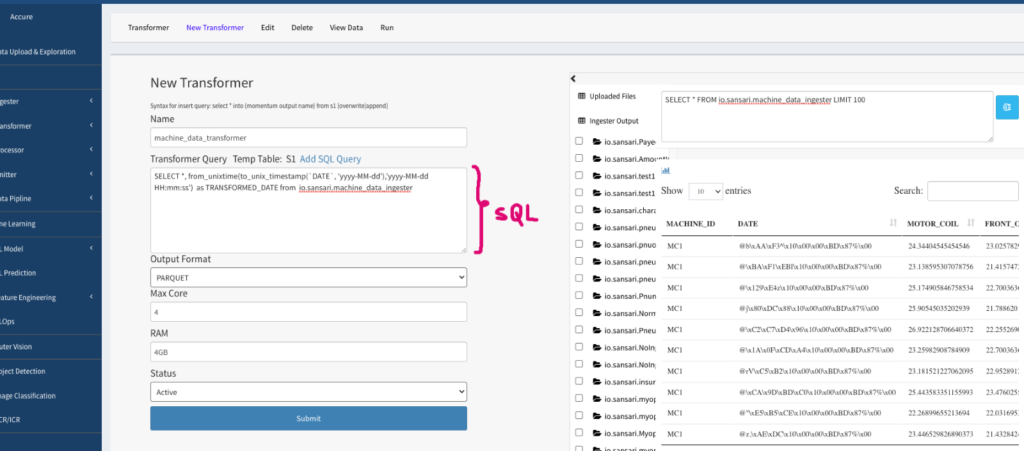
Figure 2.5: Transformer example showing SQL statement
- Name: give a unique and meaningful name to this transformer
- Transformer Query: Write SQL statement to transform your data. Notice that the table name contains the first two letters of the components that generated data, followed by a dot, followed by the username and another dot, and the name of the component. For example, our datasource table name is “io.sansari.machine_data_ingester” where “io” stands for ingester output”.
- In our example, the SQL statements to convert binary DATE into human readable date is:
SELECT *, from_unixtime(to_unix_timestamp(`DATE`, ‘yyyy-MM-dd’),’yyyy-MM-dd HH:mm:ss’) as TRANSFORMED_DATE from io.sansari.machine_data_ingester
- Select output format, parquet being the default.
- Max core: specify how many CPU core of the cluster your transformer should run on concurrently to perform parallel operations. For example, 4 cores of CPU is good enough for small to mid-size data. For larger dataset, the more that core, the faster the processing will be.
- RAM: specify how much RAM each CPU core should occupy. 4GB per core is a good default for most cases and should be larger for very large dataset.
- Submit to save the transformer configuration. If everything goes well, the page will transition to the Transformer Home page.
- From the Transformer Home page, check the transformer just created, and click the “Run” button located at the top menu bar.
- It might take a few seconds to provision and start the transformation process, and depending on the data size, it make take some time to complete the transformation.
- Click on the “Transformer” menu option from the top menu to refresh the transformer status, shown below in Figure 2.6.
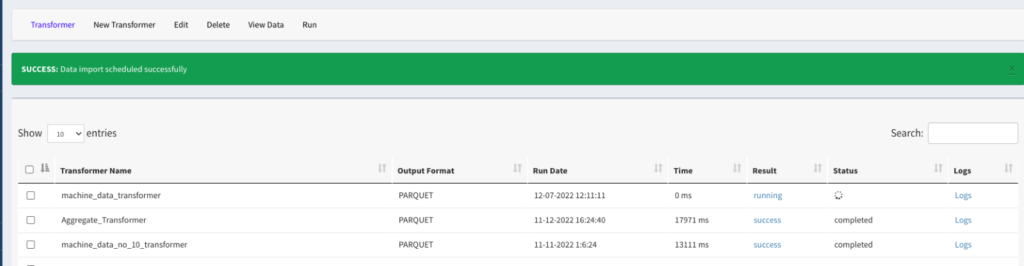
Figure 2.6: Screen showing the transformation run status.
- Click on the Logs link to monitor the logs and watch for any errors.
- After the transformer is completed successfully, checkbox, and click on “View Data” to take a quick look of the data created by the transformation (see Figure 2.7 below and notice the TRANFORMED_DATE column has human readable dates). See more on data exploration, “Exploring Data”, below.

Figure 2.7: A sample data generated by the transformer
Multi Step Transformer
To demonstrate multi-step transformation process, we will work on an example that creates training and test sets needed for machine learning model training. The steps are as follows.
Creating Training and Test Sets Using Transformer
There are many ways to create training and test sets from the dataset we ingested. This section demonstrates how to use SQL compliant transformer to create the two sets for machine learning training and test.
Assuming we want to create 80% training and 20% test sets from the original 10,000 records. We also want to randomize the data so that the training and test sets are not biased. We will create two transformers:
- The training set transformer will have a randomized 8000 records
- The test set transformer will have 2000 records that are not in the training set.
Creating Training Set
Here are the steps to create the training set:
- Expand “Transformer” and click “Transformer Home” to launch the transformer home page.
- Click “New Transformer” from the top menu to open the form to write transformation SQL. Provide a meaningful name to this transformer, e.g. machine_data_training_set
- In the Transformer Query block, write SQL statement as follows. Notice that the SQL statement contains the ingester name or a previously transformed dataset name.
- Save the Transformer.
- Select the transformer and click “Run” located at the top menu bar.
- After the transformer is successfully done, use the data exploration and interactive query tools to check the data.
SELECT * FROM tr.sansari.machine_data_transformer order by RAND() limit 8000
Listing 2: Transformer SQL to generate training set
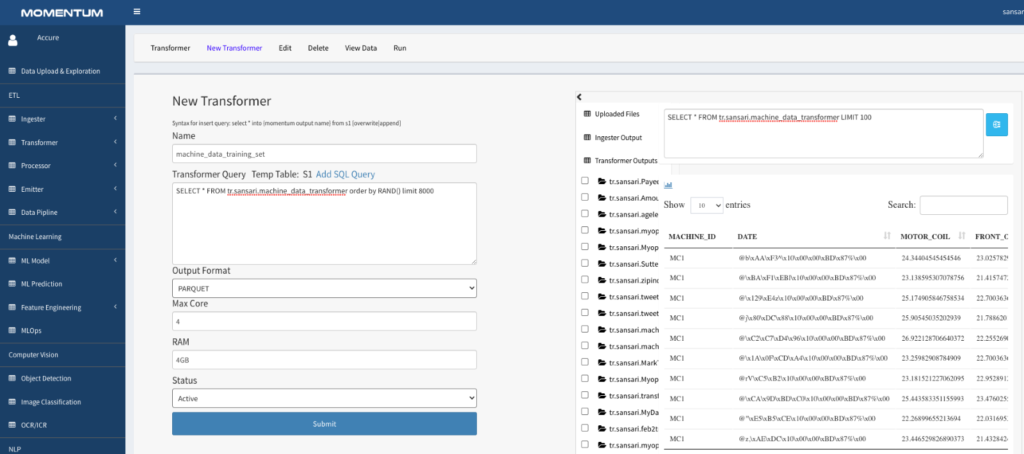
Figure 2.8: Transformer to create training set
Notice that the transformer page shows a list of data sources on the right-side panel. You can click on any data item to see the data in tabular form. This view is provided to give an aid to the user while writing the SQL statements for the transformer.
Creating Test Set
This section demonstrates a multi-step transformation process, a powerful way of transforming complex data into meaningful forms. Here are the steps to create the test set:
- Click New Transformer at the top menu bar. Give a meaningful name to the transformer, such as machine_data_test_set
- Write a simple “Select” statement to load the data from the original data source, e.g. machine_data_transformer. Logically, the output of this statement will be stored in a temp table called “S1”.
SELECT * FROM tr.sansari.machine_data_transformer
Listing 3: SQL statement to load all the data from a transformer
- Click “Add SQL Query” to open another query block. We will write a simple SQL statement to load the data from the training set transformer that we created previously. The output of this SQL is logically stored in another temp table called “S2”.
SELECT * FROM tr.sansari.machine_data_training_set
Listing 4: SQL statement to load transformer data that created training set
- The final SQL statement will simply perform a MINUS operation between the two SQL statements above.
select * from s1 minus select * from s2
Listing 5: SQL statement to perform MINUS operation
The following Figure 2.9 shows the three SQL statements as you will see in Momentum Transformer page.
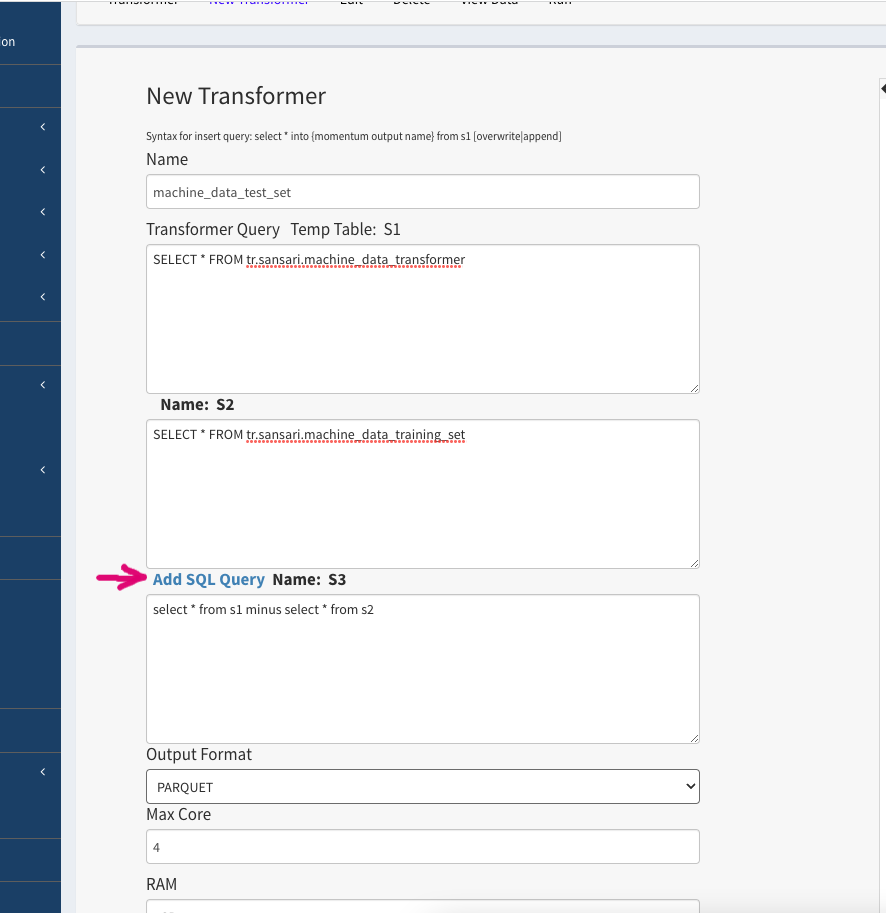
Figure 2.9: Multi-step transformer to create test set
- Save and run this transformer. Check the result from the Data Upload and Exploration utilities.
Notes:
- If the column name is a SQL reserved keyword, such as DATE, backquote that column, e.g. `DATE` within the SQL statements.
- The transformer stores data of the last run only. In other words, if you run the transformer multiple times, only the last run output will be stored in transformer.
- Add the transformer in a data pipeline if you want incremental data or full data as a result of the transformation. See “Setting Data Pipeline” section.